
Menu
Precision-Enhanced RAG: Advanced Document Retrieval and Compression with Ensemble Retrievers and BgeRerank Optimization with Docker
Precision-Enhanced RAG: Advanced Document Retrieval and Compression with Ensemble Retrievers and BgeRerank Optimization with Docker
The primary goal of this code is to create an advanced Streamlit-based application that serves as a retrieval-augmented generation (RAG) assistant.
The app allows users to upload documents, process them, and query them interactively with the help of a large language model (LLM). The system retrieves the most relevant information from the uploaded documents and provides concise, accurate answers to user queries.
Here’s a breakdown of everything I did
Importing Libraries: I imported several libraries and modules essential for building the application. This includes Streamlit for the user interface, Langchain for the NLP components, and HuggingFace for generating embeddings.
Custom Functions: I created two custom functions to enhance the user experience: display_top_bge_ranked_docs(docs): This function displays the top-ranked documents in the Streamlit sidebar. It takes the documents as input and shows the first 500 characters along with a relevance score. on_btn_click(): This function clears the chat history whenever the user clicks the ‘Clear message’ button.
Main Function: The main() function is the core of the application, coordinating the entire process from start to finish.
Customization Options: I provided the user with the ability to input their GROQ API key and select a model from the sidebar. The selected model is then used to instantiate the large language model (LLM) with ChatGroq. If the API key is invalid, a warning is displayed to alert the user.
Document Upload and Processing: I enabled users to upload files, such as PDFs, through the sidebar. The content of these files is read and extracted using the PyPDFLoader. Then, I split the text into manageable chunks using RecursiveCharacterTextSplitter to make it easier to process.
Vector Store Creation: I created a Chroma vector store to store the document chunks and their embeddings. These embeddings are generated using the HuggingFaceEmbeddings model. The vector store is designed to persist the embeddings, allowing for efficient retrieval later on.
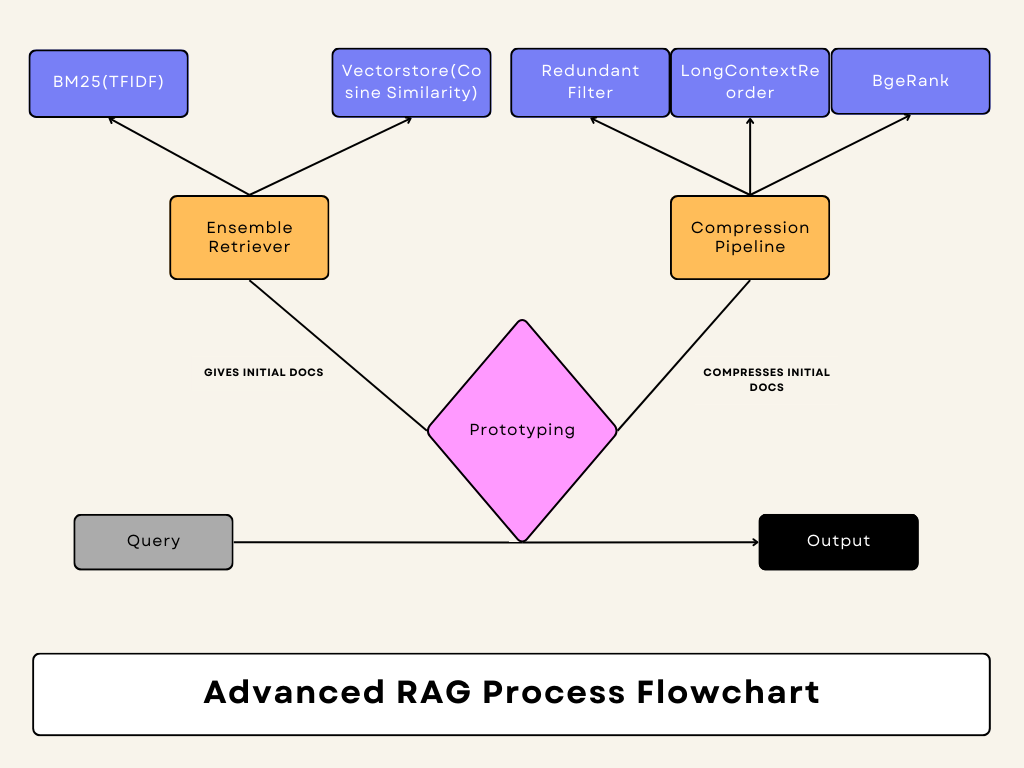
Retrievers and Rerankers: I instantiated two retrievers: BM25Retriever for keyword-based retrieval and a vector store-based retriever (vs_retriever). Then, I combined the results from both retrievers using an EnsembleRetriever. To optimize the retrieval, I established a DocumentCompressorPipeline using transformers like EmbeddingsRedundantFilter, LongContextReorder, and a custom reranker, BgeRerank.
Query Handling: When a user inputs a query, the compression_pipeline retrieves and ranks the most relevant documents. These ranked documents are displayed in the sidebar using display_top_bge_ranked_docs. I used a prompt template (QA_PROMPT) to structure the LLM’s response, ensuring it’s clear and concise. The query is passed to the ConversationalRetrievalChain, which uses the LLM to generate an answer based on the retrieved documents and the user’s chat history. The chat history is then updated with the latest query and response, and the conversation is displayed using display_chat_history.
BgeRerank Class: I created a custom class called BgeRerank, extending BaseDocumentCompressor. This class uses the BAAI/bge-reranker-large model to rerank documents based on their relevance to the user’s query. The bge_rerank method generates scores for each document relative to the query and returns the top-ranked documents. The compress_documents method then compresses the documents by selecting the top ones based on their relevance scores.
Docker Integration: I also ensured that the entire application can be containerized using Docker. This makes it easy to deploy the app in various environments without worrying about dependencies or setup. I wrote a Dockerfile that defines the necessary steps to build and run the application in a Docker container, ensuring consistency across different platforms.
Running the Application: Finally, the main() function is executed when the script is run directly. It initializes the chat history if it’s not already present in the session state and gets the application up and running.
In Summary:
I designed the application to process uploaded documents by splitting them into chunks and storing them in a vector store with embeddings for future retrieval. When a user enters a query, the system retrieves the most relevant document chunks, ranks them, and uses the LLM to generate an accurate, concise response. The user can interact with the application through the Streamlit interface, uploading files, entering queries, and clearing the chat history as needed. Additionally, by containerizing the application with Docker, deployment becomes straightforward and consistent across different environments.
Our Latest Projects
Far far away, behind the word mountains, far from the countries Vokalia and Consonantia

About
An AI Geek and a lifelong learner, who thrives in coding and problem-solving through ML, DL, and LLMs.
Copyright ©2024 All rights reserved.