Implementing Spark Pipelines for Mobile Usage and Behavior Analytics (Leveraging SparkSQL)
Implementing Spark Pipelines for Mobile Usage and Behavior Analytics (Leveraging SparkSQL)
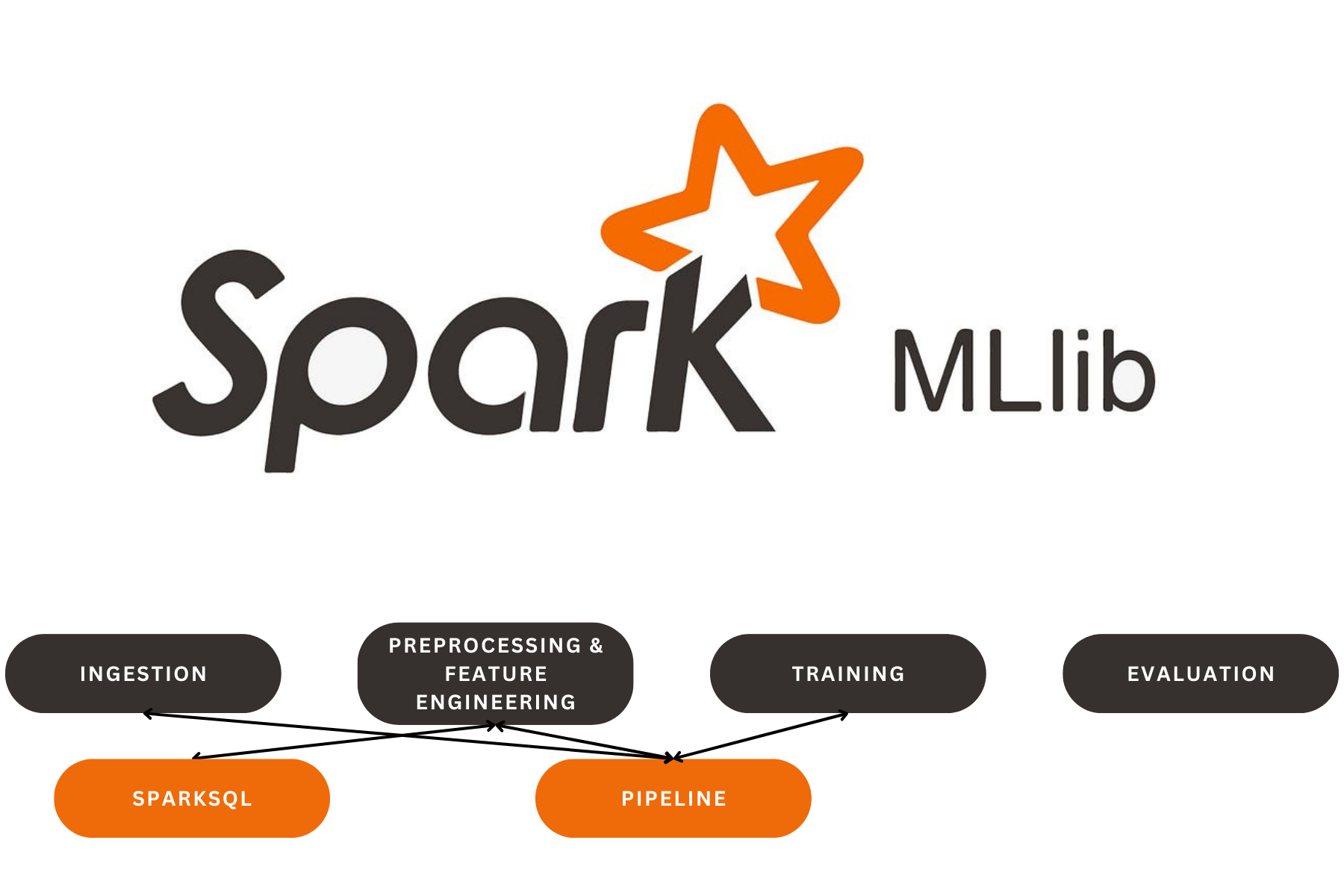
In this project, I built Spark pipelines to process and analyze mobile usage and behavior data. I leveraged SparkSQL to perform complex queries and used Spark’s distributed processing capabilities to handle large-scale mobile data, enabling efficient analysis of user behavior patterns and usage metrics.
How It Works
I handled the data ingestion process by reading mobile usage data into a Spark DataFrame. I set up the pipeline to read from various formats like CSV, JSON, and Parquet.
I added a gender_null_acc accumulator to track the number of records where the ‘Gender’ field was missing.
Cleaning the ingested data includes handling missing values, converting data types, and other transformations needed to prepare the data for analysis.
I also focused on creating new features that help in analyzing user behavior more effectively. One important transformation was by determining the average app usage time per age group and adds it as a new column, AvgAppUsageByAge, in the DataFrame using PySpark’s Window and avg functions.
Also trained an LR model and save the model using Spark MLlib. Also developed an evaluation script to compute metrics such as accuracy, precision, and recall to assess how well the models are performing on test data.
I included various SparkSQL queries in this script to derive insights from the data. These queries help me generate reports on user behavior patterns, such as which age groups use certain apps the most.
This file contains reusable utility functions that I used throughout the project, such as functions for logging, handling configuration files, and other helper functions.
I implemented a pipeline that orchestrates the entire data flow from ingestion, preprocessing, feature engineering, model training, and evaluation.