
Menu
Boosting Algorithms Notebook to Predict Flood Part 1
Boosting Algorithms Notebook to Predict Flood Part 2
# Import necessary libraries
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from matplotlib.ticker import MaxNLocator
# Ignore warnings
import warnings
warnings.filterwarnings('ignore')
# Set the style of matplotlib
%matplotlib inline
plt.style.use('fivethirtyeight')
# Load training and testing datasets
train = pd.read_csv('/kaggle/input/playground-series-s4e5/train.csv', index_col='id')
test = pd.read_csv('/kaggle/input/playground-series-s4e5/test.csv', index_col='id')
# View the general information of the training dataset
train.info()
# Store the names of feature columns
initial_features = list(test.columns)
# Check if there are any missing values
train.isna().sum()
# Check if there are any missing values
test.isnull().sum()
# View the value of the target column
train['FloodProbability'].unique()
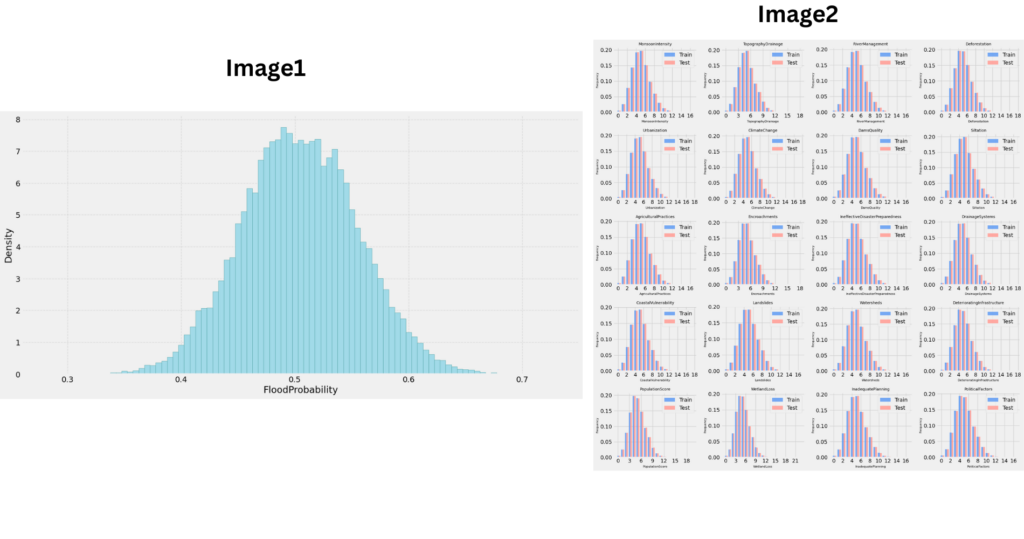
# Visualization of target distribution
plt.figure(figsize=(16, 8))
plt.hist(train['FloodProbability'], bins=np.linspace(0.2825, 0.7275, 90),
density=True, color='#add8e6', edgecolor='#5f9ea0')
plt.grid(True, linestyle='--', alpha=0.6)
plt.xlabel('FloodProbability')
plt.ylabel('Density')
plt.show()
# Visualization of feature distributions
# Create a grid of subplots
fig, axs = plt.subplots(5, 4, figsize=(16, 16))
# Iterate over each feature and corresponding axis
for col, ax in zip(initial_features, axs.ravel()):
# Calculate and plot the relative frequency of each value in the training set
vc_train = train[col].value_counts(normalize=True)
ax.bar(vc_train.index, vc_train, width=0.4, align='center', alpha=0.8, label='Train', color='cornflowerblue')
# Calculate and plot the relative frequency of each value in the test set
vc_test = test[col].value_counts(normalize=True)
ax.bar(vc_test.index + 0.4, vc_test, width=0.4, align='center', alpha=0.6, label='Test', color='salmon')
# Set title and axis labels
ax.set_title(col, fontsize=10)
ax.set_xlabel(col, fontsize=8)
ax.set_ylabel('Frequency', fontsize=8)
# Display only integer labels
ax.xaxis.set_major_locator(MaxNLocator(integer=True))
# Add legend to each plot
ax.legend()
plt.tight_layout()
plt.show()
# Visualization of feature distributions
# Function to plot histograms and boxplots
def plot_histograms_and_boxplots(data, columns, color):
num_plots = len(columns)
fig, axes = plt.subplots(num_plots, 2, figsize=(16, num_plots * 5))
for i, col in enumerate(columns):
# Plot histogram
sns.histplot(data[col], ax=axes[i, 0], bins=50, color=color, kde=False)
axes[i, 0].set_title(f'Histogram of {col}', fontsize=12)
axes[i, 0].set_xlabel(col, fontsize=10)
axes[i, 0].set_ylabel('Count', fontsize=10)
axes[i, 0].grid(False)
# Add border lines
for spine in axes[i, 0].spines.values():
spine.set_visible(True)
spine.set_linewidth(1)
spine.set_color('black')
# Plot boxplot
sns.boxplot(y=data[col], ax=axes[i, 1], color=color, width=0.8, linewidth=1)
axes[i, 1].set_title(f'Boxplot of {col}', fontsize=12)
axes[i, 1].set_xlabel('Count', fontsize=10)
axes[i, 1].set_ylabel(col, fontsize=10)
axes[i, 1].grid(False)
# Add border lines
for spine in axes[i, 1].spines.values():
spine.set_visible(True)
spine.set_linewidth(1)
spine.set_color('black')
plt.tight_layout()
plt.show()
# Plot charts
plot_histograms_and_boxplots(train, initial_features, color='salmon')
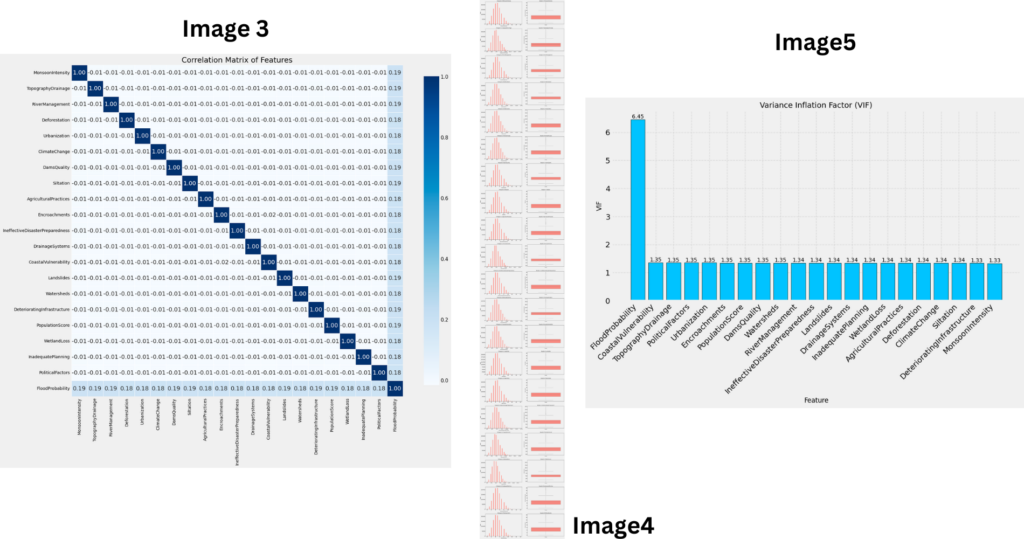
# Visualization of the correlation matrix
# Calculate the correlation matrix
corr_features = initial_features + ['FloodProbability']
# Use pandas' corr function to directly compute the correlation matrix
corr_matrix = train[corr_features].corr()
plt.figure(figsize=(16, 16))
# Plot the heatmap, add grid lines and adjust font sizes
cmap = sns.color_palette("Blues", as_cmap=True)
ax = sns.heatmap(corr_matrix, annot=True, fmt=".2f", cmap=cmap,
linewidths=.5, cbar_kws={"shrink": .8}, square=True,
xticklabels=corr_features, yticklabels=corr_features)
plt.title('Correlation Matrix of Features', fontsize=18)
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
# Adjust the color bar size
cbar = ax.collections[0].colorbar
cbar.ax.tick_params(labelsize=12)
plt.show()
# Calculate the Variance Inflation Factor (VIF) for each independent variable
from statsmodels.stats.outliers_influence import variance_inflation_factor
from statsmodels.tools.tools import add_constant
# Add a constant column to the training dataset, typically used for the intercept in linear regression
train_with_const = add_constant(train)
# Initialize a DataFrame to store feature names and their VIF values
vif_data = pd.DataFrame({
"feature": train_with_const.columns, # Feature names
"VIF": [
variance_inflation_factor(train_with_const.values, i) # Calculate VIF for each feature
for i in range(train_with_const.shape[1])
]
})
vif_data
# Visualize the Variance Inflation Factor (VIF)
# Sort the VIF data in descending order by VIF value
vif_data = vif_data[vif_data['feature'] != 'const']
vif_data_sorted = vif_data.sort_values('VIF', ascending=False)
plt.figure(figsize=(12, 6))
bars = plt.bar(vif_data_sorted['feature'], vif_data_sorted['VIF'],
color='deepskyblue', edgecolor='black')
# Add specific VIF values on top of each bar
for bar in bars:
yval = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2, yval, round(yval, 2),
va='bottom', ha='center', fontsize=10)
plt.xlabel('Feature', fontsize=12)
plt.ylabel('VIF', fontsize=12)
plt.title('Variance Inflation Factor (VIF)', fontsize=14)
plt.grid(True, linestyle='--', alpha=0.6)
plt.xticks(rotation=45, ha='right')
plt.show()
# Collect unique values for all feature columns in the training and testing datasets
unique_vals = []
for df in [train, test]:
for col in initial_features:
unique_vals += list(df[col].unique())
unique_vals = list(set(unique_vals))
from sklearn.preprocessing import StandardScaler
# Generate new features
def getFeats(df):
# Standardize numerical feature columns
# Ensuring different scale features have the same scale, which helps the model's learning and convergence.
scaler = StandardScaler()
# Create interaction features
# Climate and human activity interaction features: Reflecting the combined impact of climate change intensity and human activities such as deforestation, urbanization, etc.
df['ClimateAnthropogenicInteraction'] = (df['MonsoonIntensity'] + df['ClimateChange']) * \
(df['Deforestation'] + df['Urbanization'] + df['AgriculturalPractices'] + df['Encroachments'])
# Infrastructure and disaster management interaction features: Examining the interaction between infrastructure quality and inadequate disaster preparedness.
df['InfrastructurePreventionInteraction'] = (df['DamsQuality'] + df['DrainageSystems'] + df['DeterioratingInfrastructure']) * \
(df['RiverManagement'] + df['IneffectiveDisasterPreparedness'] + df['InadequatePlanning'])
# Create descriptive statistical features
# Basic statistics: Providing the model with simple statistical descriptions of the raw data.
df['sum'] = df[initial_features].sum(axis=1) # Sum of features
df['std'] = df[initial_features].std(axis=1) # Standard deviation
df['mean'] = df[initial_features].mean(axis=1) # Mean
df['max'] = df[initial_features].max(axis=1) # Maximum value
df['min'] = df[initial_features].min(axis=1) # Minimum value
df['mode'] = df[initial_features].mode(axis=1)[0] # Mode
df['median'] = df[initial_features].median(axis=1) # Median
df['q_25th'] = df[initial_features].quantile(0.25, axis=1) # 25th percentile
df['q_75th'] = df[initial_features].quantile(0.75, axis=1) # 75th percentile
df['skew'] = df[initial_features].skew(axis=1) # Skewness
df['kurt'] = df[initial_features].kurt(axis=1) # Kurtosis
# Range feature: Check if the sum of features falls within a specific range.
df['sum_72_76'] = df['sum'].isin(np.arange(72, 76))
# Quantile features: Providing the model with more detailed data distribution information.
for i in range(10, 100, 10):
df[f'{i}th'] = df[initial_features].quantile(i / 100, axis=1)
# Other mathematical features
df['harmonic'] = len(initial_features) / df[initial_features].apply(lambda x: (1/x).mean(), axis=1) # Harmonic mean
df['geometric'] = df[initial_features].apply(lambda x: x.prod()**(1/len(x)), axis=1) # Geometric mean
df['zscore'] = df[initial_features].apply(lambda x: (x - x.mean()) / x.std(), axis=1).mean(axis=1) # Z-score mean
df['cv'] = df[initial_features].std(axis=1) / df[initial_features].mean(axis=1) # Coefficient of variation
df['Skewness_75'] = (df[initial_features].quantile(0.75, axis=1) - df[initial_features].mean(axis=1)) / df[initial_features].std(axis=1) # 75th percentile skewness
df['Skewness_25'] = (df[initial_features].quantile(0.25, axis=1) - df[initial_features].mean(axis=1)) / df[initial_features].std(axis=1) # 25th percentile skewness
df['2ndMoment'] = df[initial_features].apply(lambda x: (x**2).mean(), axis=1) # Second moment
df['3rdMoment'] = df[initial_features].apply(lambda x: (x**3).mean(), axis=1) # Third moment
df['entropy'] = df[initial_features].apply(lambda x: -1*(x*np.log(x)).sum(), axis=1) # Entropy
# Unique value count features: Counting the occurrences of each unique value in the dataset, helps understand data discreteness.
for v in unique_vals:
df['cnt_{}'.format(v)] = (df[initial_features] == v).sum(axis=1)
df[initial_features] = scaler.fit_transform(df[initial_features])
return df
# Add new features to the training and testing datasets
train['type'] = 0
test['type'] = 1
all_data = pd.concat([train, test], axis=0)
all_data = getFeats(all_data)
all_data
# Split training and testing datasets
train = all_data[all_data['type']==0]
test = all_data[all_data['type']==1]
# Split the features and target variable
X_train = train.drop(['FloodProbability', 'type'], axis=1)
y_train = train['FloodProbability']
X_test = test.drop(['FloodProbability', 'type'], axis=1)
XGBoost
from sklearn.model_selection import KFold
# Parameter settings
xgb_params = {
'n_estimators':8000,
'max_depth': 10,
'tree_method': 'gpu_hist',
'learning_rate': 0.01,
'random_state':0,
}
# Initialize variables
spl = 10
xgb_test_preds = np.zeros((len(X_test)))
xgb_val_preds = np.zeros((len(X_train)))
xgb_val_scores, xgb_train_scores = [], []
# Define cross-validation
cv = KFold(spl, shuffle=True, random_state=42)
# Cross-validation loop
for fold, (train_ind, valid_ind) in enumerate(cv.split(X_train, y_train)):
# Data splitting
X_fold_train = X_train.iloc[train_ind]
y_fold_train = y_train.iloc[train_ind]
X_val = X_train.iloc[valid_ind]
y_val = y_train.iloc[valid_ind]
# Model initialization and training
model = XGBRegressor(**xgb_params)
model.fit(X_fold_train, y_fold_train,
eval_set=[(X_fold_train, y_fold_train), (X_val, y_val)],
early_stopping_rounds=70,
verbose=100)
# Predict and evaluate
y_pred_trn = model.predict(X_fold_train)
y_pred_val = model.predict(X_val)
train_r2 = r2_score(y_fold_train, y_pred_trn)
val_r2 = r2_score(y_val, y_pred_val)
print("Fold:", fold, " Train R2:", np.round(train_r2, 5), " Val R2:", np.round(val_r2, 5))
# Store predictions
xgb_test_preds += model.predict(X_test) / spl
xgb_val_preds[valid_ind] = model.predict(X_val)
xgb_val_scores.append(val_r2)
print("-" * 50)
# Print the average validation score
print("Average Validation R2:", np.mean(xgb_val_scores))
results = pd.DataFrame(X_test.index)
results['FloodProbability'] = xgb_test_preds
results.to_csv('result_xgb.csv', index=False)
results
CatBoost
from sklearn.model_selection import KFold
# Parameter settings
cat_params = {
'n_estimators':8000,
'random_state':0,
'learning_rate': 0.011277016304363601,
'depth': 8,
'subsample': 0.8675506657380021,
# 'colsample_bylevel': 0.7183884158632279,
'min_data_in_leaf': 98,
'task_type': 'GPU',
'bootstrap_type': 'Bernoulli'
}
# Initialize variables
spl = 10
cat_test_preds = np.zeros((len(X_test)))
cat_val_preds = np.zeros((len(X_train)))
cat_val_scores, cat_train_scores = [], []
# Define cross-validation
cv = KFold(spl, shuffle=True, random_state=42)
# Cross-validation loop
for fold, (train_ind, valid_ind) in enumerate(cv.split(X_train, y_train)):
# Data splitting
X_fold_train = X_train.iloc[train_ind]
y_fold_train = y_train.iloc[train_ind]
X_val = X_train.iloc[valid_ind]
y_val = y_train.iloc[valid_ind]
# Model initialization and training
model = CatBoostRegressor(**cat_params)
model.fit(X_train, y_train,
eval_set=[(X_val, y_val)],
early_stopping_rounds=70,
verbose=100)
# Prediction and evaluation
y_pred_trn = model.predict(X_fold_train)
y_pred_val = model.predict(X_val)
train_r2 = r2_score(y_fold_train, y_pred_trn)
val_r2 = r2_score(y_val, y_pred_val)
print("Fold:", fold, " Train R2:", np.round(train_r2, 5), " Val R2:", np.round(val_r2, 5))
# Store predictions
cat_test_preds += model.predict(X_test) / spl
cat_val_preds[valid_ind] = model.predict(X_val)
cat_val_scores.append(val_r2)
print("-" * 50)
# Print the average validation score
print("Average Validation R2:", np.mean(cat_val_scores))
results = pd.DataFrame(X_test.index)
results['FloodProbability'] = cat_test_preds
results.to_csv('result_cat.csv', index=False)
results
LightGBM
This function processes user queries by using the provided chain and updating the chat history.
import lightgbm as lgbm
from sklearn.model_selection import KFold
# Parameter settings
params = {
'verbosity': -1,
'n_estimators': 550,
'learning_rate': 0.02,
'num_leaves': 250,
'max_depth': 10,
}
# Initialize variables
spl = 10
lgbm_test_preds = np.zeros((len(X_test)))
lgbm_val_preds = np.zeros((len(X_train)))
lgbm_val_scores, lgbm_train_scores = [], []
# Define cross-validation
cv = KFold(spl, shuffle=True, random_state=42)
# Cross-validation loop
for fold, (train_ind, valid_ind) in enumerate(cv.split(X_train, y_train)):
# Data splitting
X_fold_train = X_train.iloc[train_ind]
y_fold_train = y_train.iloc[train_ind]
X_val = X_train.iloc[valid_ind]
y_val = y_train.iloc[valid_ind]
# Model initialization and training
model = lgbm.LGBMRegressor(boosting_type='gbdt',
n_estimators=8000,
learning_rate=0.012,
# device='gpu',
num_leaves=250,
subsample_for_bin=165700,
min_child_samples=114,
reg_alpha=2.075e-06,
reg_lambda=3.839e-07,
colsample_bytree=0.9634,
subsample=0.9592,
max_depth=10,
random_state=0,
verbosity=-1
)
model.fit(X_fold_train, y_fold_train,
eval_set=[(X_val, y_val)],
callbacks=[lgbm.early_stopping(stopping_rounds=50), lgbm.log_evaluation(100)])
# Predict and evaluate
y_pred_trn = model.predict(X_fold_train)
y_pred_val = model.predict(X_val)
train_r2 = r2_score(y_fold_train, y_pred_trn)
val_r2 = r2_score(y_val, y_pred_val)
print("Fold:", fold, " Train R2:", np.round(train_r2, 5), " Val R2:", np.round(val_r2, 5))
# Store predictions
lgbm_test_preds += model.predict(X_test) / spl
lgbm_val_preds[valid_ind] = model.predict(X_val)
lgbm_val_scores.append(val_r2)
print("-" * 50)
# Print the average validation score
print("Average Validation R2:", np.mean(lgbm_val_scores))
results = pd.DataFrame(X_test.index)
results['FloodProbability'] = lgbm_test_preds
results.to_csv('result_lgbm.csv', index=False)
results
Ensemble
ensemble_test_preds = lgbm_test_preds*0.5 + cat_test_preds*0.2 + xgb_test_preds*0.3
results = pd.DataFrame(X_test.index)
results['FloodProbability'] = ensemble_test_preds
results.to_csv('result_ensemble.csv', index=False)
results
Conclusion
Combining the predictions from XGBoost, CatBoost, and LightGBM using a weighted average to create an ensemble prediction, and save the results.
This comprehensive workflow includes data loading, exploration, feature engineering, model training, and ensemble predictions, with detailed visualizations and evaluations at each step.
Here’s a brief summary of each part:
Library Imports and Style Settings:Import necessary libraries for data manipulation, visualization, and machine learning.
Set the plotting style and configure to ignore warnings.- Data Loading:Load training and testing datasets from CSV files.
- Data Overview:Display general information about the datasets, including column names and missing values.
- Target Variable Analysis:Examine and visualize the distribution of the target variable
FloodProbability. - Feature Distributions:Visualize the distribution of feature variables in both training and testing datasets.
- Correlation Matrix:Calculate and visualize the correlation matrix for the features and the target variable.
- Variance Inflation Factor (VIF):Calculate and visualize the VIF to detect multicollinearity among features.
- Feature Engineering:Create interaction features, statistical features, and other mathematical features.Scale the features using
StandardScaler. - Data Modeling:Split the dataset into features and target variable.Train models using XGBoost, CatBoost, and LightGBM with K-Fold cross-validation, make predictions, and save the results.
- Ensemble:Combine the predictions from XGBoost, CatBoost, and LightGBM using a weighted average to create an ensemble prediction, and save the results.
Our Latest Projects
Far far away, behind the word mountains, far from the countries Vokalia and Consonantia

About
An AI Geek and a lifelong learner, who thrives in coding and problem-solving through ML, DL, and LLMs.
Copyright ©2024 All rights reserved.