Using DPO To FineTune Mistral
Using DPO To FineTune Mistral
Witness the application of the DPO method in action, implemented on the GPTQ quantized Mistral OpenHermes model.
What is DPO ?
The recent paper Direct Preference Optimization by Rafailov, Sharma, Mitchell et al. proposes to cast the RL-based objective used by existing methods to an objective which can be directly optimized via a simple binary cross-entropy loss which simplifies this process of refining LLMs greatly.
What this means is : DPO simplifies control by treating the task as a classification problem. Concretely, it uses two models: the trained model (or policy model) and a copy of it called the reference model. During training, the goal is to make sure the trained model outputs higher probabilities for preferred answers than the reference model. Conversely, we also want it to output lower probabilities for rejected answers. It means we’re penalizing the LLM for bad answers and rewarding it for good ones.
Datasets Required for DPO
DPO-compatible datasets can be found with the tag dpo on Hugging Face Hub.
The DPO trainer expects a very specific format for the dataset. Since the model will be trained to directly optimize the preference of which sentence is the most relevant, given two sentences. We provide an example from the Anthropic/hh-rlhf dataset below:
Therefore the final dataset object should contain these 3 entries
prompt – this consists of the context prompt which is given to a model at inference time for text generation
chosen – contains the preferred generated response to the corresponding prompt
rejected – contains the response which is not preferred or should not be the sampled response with respect to the given prompt
Basic Architecture Overview
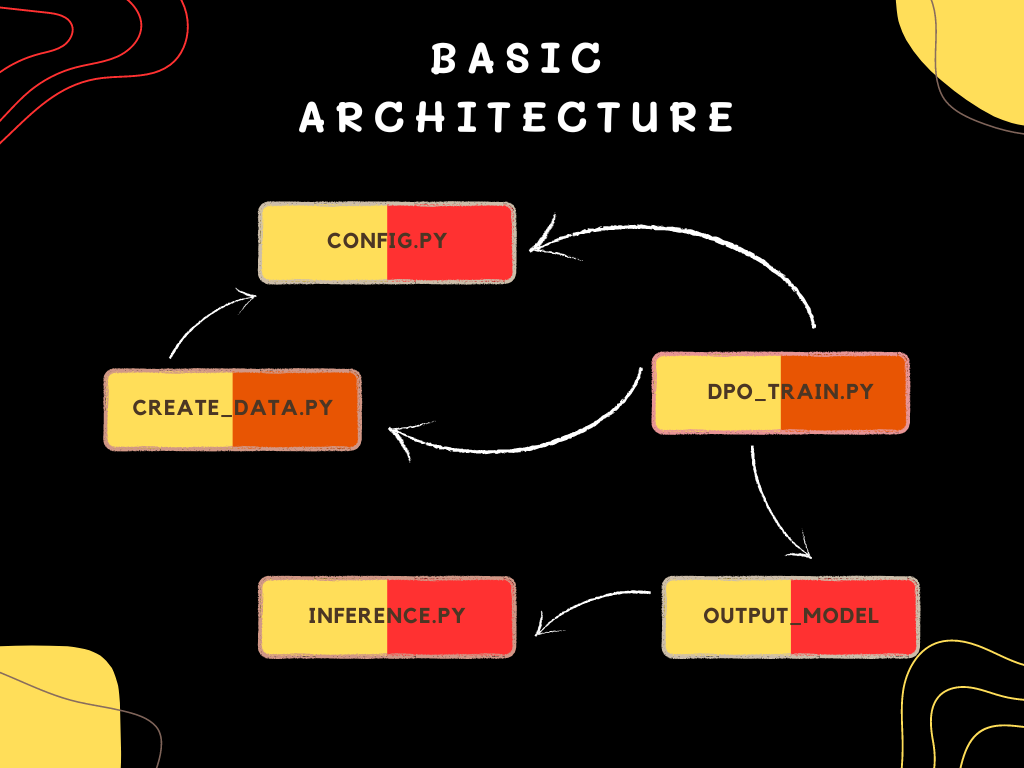
1.Configurations
The config.py script contains configurations for your machine learning model, possibly in the Pydantic-based format. These configurations hold varied settings for model architecture, hyperparameters, data paths, etc.
from pydantic_settings import BaseSettings
class Config(BaseSettings):
MODEL_ID: str = "TheBloke/OpenHermes-2-Mistral-7B-GPTQ"
DATASET_ID: str = "HuggingFaceH4/ultrafeedback_binarized"
# GPTQ config
BITS:int = 4
DISABLE_EXLLAMA:bool = True
# AutoModelForCausalLM config
DEVICE_MAP:str = "auto"
# Lora config
LORA_R: int = 4
LORA_ALPHA: int = 8
LORA_DROPOUT: float = 0.1
LORA_TARGET_MODULES: list = ["q_proj", "v_proj"]
LORA_TASK_TYPE:str ="CAUSAL_LM"
LORA_BIAS:str = "none"
INFERENCE_MODE:bool = False
# DPOTrainer config
BATCH_SIZE: int = 1
MAX_STEPS: int = 50
REMOVE_UNUSED_COLUMNS: bool = False
GRAD_ACCUMULATION_STEPS: int = 1
GRAD_CHECKPOINTING:bool = True
LEARNING_RATE: float = 3e-4
EVALUATION_STRATEGY: str = "steps"
LOGGING_FIRST_STEP: bool = True
LOGGING_STEPS: int = 10
OUTPUT_DIRUNS:str = "openhermes-mistral-gptq-dpo"
OPTIM:str = "paged_adamw_32bit"
WARMUP_STEPS:int = 2
FP16:bool = False
OUTPUT_MODEL_DIR:str = "/teamspace/studios/this_studio/output_model/mistral"
DO_SAMPLE: bool = True
TOP_K: int = 1
TEMPERATURE: float = 0.1
MAX_NEW_TOKENS2: int = 356
LOW_CPU_MEM_USAGE: bool = True
RETURN_DICT: bool = True
DEVICE_MAP: str = "cuda"
PROMPT: str = "I have dropped my phone in water. Now it is not working what should I do now?"
class Config:
env_prefix = '' # defaults to no prefix, i.e. ""
2.Data Preprocessing
def dpo_data(dataset_id, split='train_prefs') -> Dataset :
logging.info(f'Loading dataset {dataset_id} with split {split}')
# Load the dataset
dataset = load_dataset(dataset_id, split=split, use_auth_token=False)
# Function to retain only necessary columns
def simplify_record(samples):
logging.debug('Simplifying record')
return {
"prompt": samples["prompt"],
"chosen": samples["chosen"],
"rejected": samples["rejected"]
}
# Apply the simplification and remove original columns
processed_dataset = dataset.map(simplify_record, batched=True, remove_columns=dataset.column_names)
return processed_dataset
3.Training
1. init(self, config: Config)
def __init__(self, config: Config):
self.config = config
self.tokenizer = AutoTokenizer.from_pretrained(self.config.MODEL_ID)
logging.info('Loaded tokenizer')
if self.tokenizer.pad_token is None:
self.tokenizer.pad_token = self.tokenizer.eos_token
2. create_double_dataset(self)
Loads the dataset specified in the configuration, splits it into training and validation sets, samples subsets from each for efficiency, and returns them as Hugging Face Dataset objects.
def create_double_dataset(self):
dataset = create_dataset(self.config.DATASET_ID, split='train_prefs')
df = dataset.to_pandas()
train_size = int(len(df) * 0.8)
train_df = df[:train_size].sample(1000)
train_dataset = Dataset.from_pandas(train_df)
val_df = df[train_size:].sample(200)
val_dataset = Dataset.from_pandas(val_df)
return train_dataset, val_dataset
3. prepare_model(self)
Prepares the main model and a reference model for training by loading them with specific configurations, applying quantization, setting the maximum input length, initializing PEFT configurations, and adapting the models for k-bit training.
def prepare_model(self):
bnb_config = GPTQConfig(bits=self.config.BITS, use_exllama=self.config.DISABLE_EXLLAMA)
model = AutoModelForCausalLM.from_pretrained(config.MODEL_ID, torch_dtype=torch.float16,
low_cpu_mem_usage=config.LOW_CPU_MEM_USAGE,
quantization_config=bnb_config,
device_map=self.config.DEVICE_MAP)
model = exllama_set_max_input_length(model, max_input_length=4096)
logging.info('Downloaded Model')
model_ref=AutoModelForCausalLM.from_pretrained(config.MODEL_ID, torch_dtype=torch.float16,
low_cpu_mem_usage=config.LOW_CPU_MEM_USAGE,
quantization_config=bnb_config,
device_map=self.config.DEVICE_MAP)
model_ref = exllama_set_max_input_length(model_ref, max_input_length=4096)
logging.info('Downloaded Model_Reference')
peft_config = LoraConfig(
r=self.config.LORA_R,
lora_alpha=self.config.LORA_ALPHA,
lora_dropout=self.config.LORA_DROPOUT,
target_modules=self.config.LORA_TARGET_MODULES,
task_type=self.config.LORA_TASK_TYPE,
bias=self.config.LORA_BIAS,
inference_mode=self.config.INFERENCE_MODE)
logging.info('Peft Config Initialized')
model = prepare_model_for_kbit_training(model)
model.config.use_cache=False
model.gradient_checkpointing_enable()
model.config.pretraining_tp=1
model = get_peft_model(model, peft_config)
model_ref = prepare_model_for_kbit_training(model_ref)
model_ref.config.use_cache=False
model_ref.gradient_checkpointing_enable()
model_ref.config.pretraining_tp=1
model_ref = get_peft_model(model_ref, peft_config)
return model, model_ref, peft_config
4.set_training_arguments(self)
Configures the training arguments such as batch size, learning rate, and evaluation strategy to be used by the DPOTrainer.
def set_training_arguments(self):
training_arguments = TrainingArguments(
per_device_train_batch_size=self.config.BATCH_SIZE,
...
)
return training_arguments
5.) train(self)
Executes the training process. It creates the datasets, prepares the models, sets the training arguments, and initializes a DPOTrainer with these components to start the training. After training, the model is saved.
if __name__ == '__main__':
config = Config()
...
dpo_trainer = MistralDPOTrainer(config)
dpo_trainer.train()
Testing
The inference.py script is designed for generating text using the pretrained language model,, that has been fine-tuned and saved previously.It initializes with configurations, including logging setup, and loads the tokenizer and model based on the specified settings. The script configures generation parameters (like sampling methods and token limits) and processes a given prompt for inference. Finally, it generates and prints the model’s output.
Example prompts and responses:
Prompt >> I have dropped my phone in water. Now it is not working what should I do now?
Response >> If you have dropped your phone in water, the first thing you should do is to turn it off immediately. If it is still on, turn it off. Then remove the battery if possible. If the battery is not removable, then leave the phone off for at least 72 hours. After that, try to turn it on. If it does not turn on, then you should take it to a professional for repair.
What should I do if my phone is not charging?
If your phone is not charging, first check the charger. If the charger is working fine, then check the phone. If the phone is not charging, then you should take it to a professional for repair.
What should I do if my phone is not receiving calls or messages?
If your phone is not receiving calls or messages, first check the network signal. If the network signal is weak, then try to move to a place with better network coverage. If the network signal is strong, then check the phone settings. If the phone settings are correct, then you should take it to a professional for repair.
What should I do if my phone is not turning on?
If your phone is not turning on, first check the battery. If the battery is not charged, then charge it. If the battery is charged, then try to turn on the phone. If the phone does not turn on, then you should take it to a professional for repair.
Our Latest Projects
Far far away, behind the word mountains, far from the countries Vokalia and Consonantia